AI-ассистент для магазина электроники

К нам обратился небольшой интернет-магазин деталей для электроники. В неделю клиенту поступает порядка 10 000 заказов. Основу клиентской базы составляют постоянные покупатели, которых привлекает широкий ассортимент товаров, а также их понятная спецификация.
Руководство интернет-магазина большое внимание уделяет точности описаний и поддержке клиентов, а сотрудники обладают достаточной экспертизой в тех деталях для электрических схем, которые продают. Это выгодное отличие от маркетплейсов, где внешне похожие детальки часто путают, а покупатели не могут задать уточняющие вопросы. В результате клиент получает не то, что хотел.
Задача
Клиент пришел с задачей частично сократить штат и потребность в сотрудниках поддержки. Экспертиза операторов поддержки — это одновременно и сильная, и слабая сторона.
В последнее время стало все сложнее и дороже заменять ушедших работников. Много средств магазина уходило на поиск кандидатов и дальнейшее обучение.
Реализация
Мы разработали интеллектуального ассистента, который:
— Автоматизирует порядка 65-70% ответов на пользовательские вопросы, которые изначально решались вручную;
— Работает с внутренними базами знаний компании;
— Повышает точность и релевантность ответов за счет структурирования данных и умного контекстного поиска;
— Поддерживает сложные темы — от технической документации до практических советов по сборке электроники и робототехники.
Для того, чтобы повысить качество и точность ответа, поработали с хранением информации в базах знаний. Разбили ее на актуальную и архивную.
Также информацию преобразовали от страниц технического вида к виду вопрос-ответ. Построили графовую структуру ссылок на множество связанных тем.
Сделали дополнительную базу знаний со статьями по электронике и робототехнике, где описываются способы применения и соедниения тех или иных деталей друг с другом. О технических деталях реализации рассказываем ниже.
Результаты
На выходе у нас получилась система, которая может автономно отвечать на вопросы о товаре, его наличии, случаях применения и использования.
Представленные метрики замерялись на проде в течение месяца после запуска проекта.

Технологии
Вот основные технические особенности проекта:
— n8n: принимает сообщения из окна чата сайта;
— LangChain: обрабатывает запрос через LLM, использует RAG (например, знания из FAQ);
— Мы используем Qwen3-30B-A3B-2507 по API.
Заказчик не хотел селф-хостить модели из-за большой стоимости и необходимости выделения дополнительных ресурсов на мониторинг стабильности решения. Для того количества запросов, с которыми обращаются пользователи, выбранный вариант решения был оптимальным.
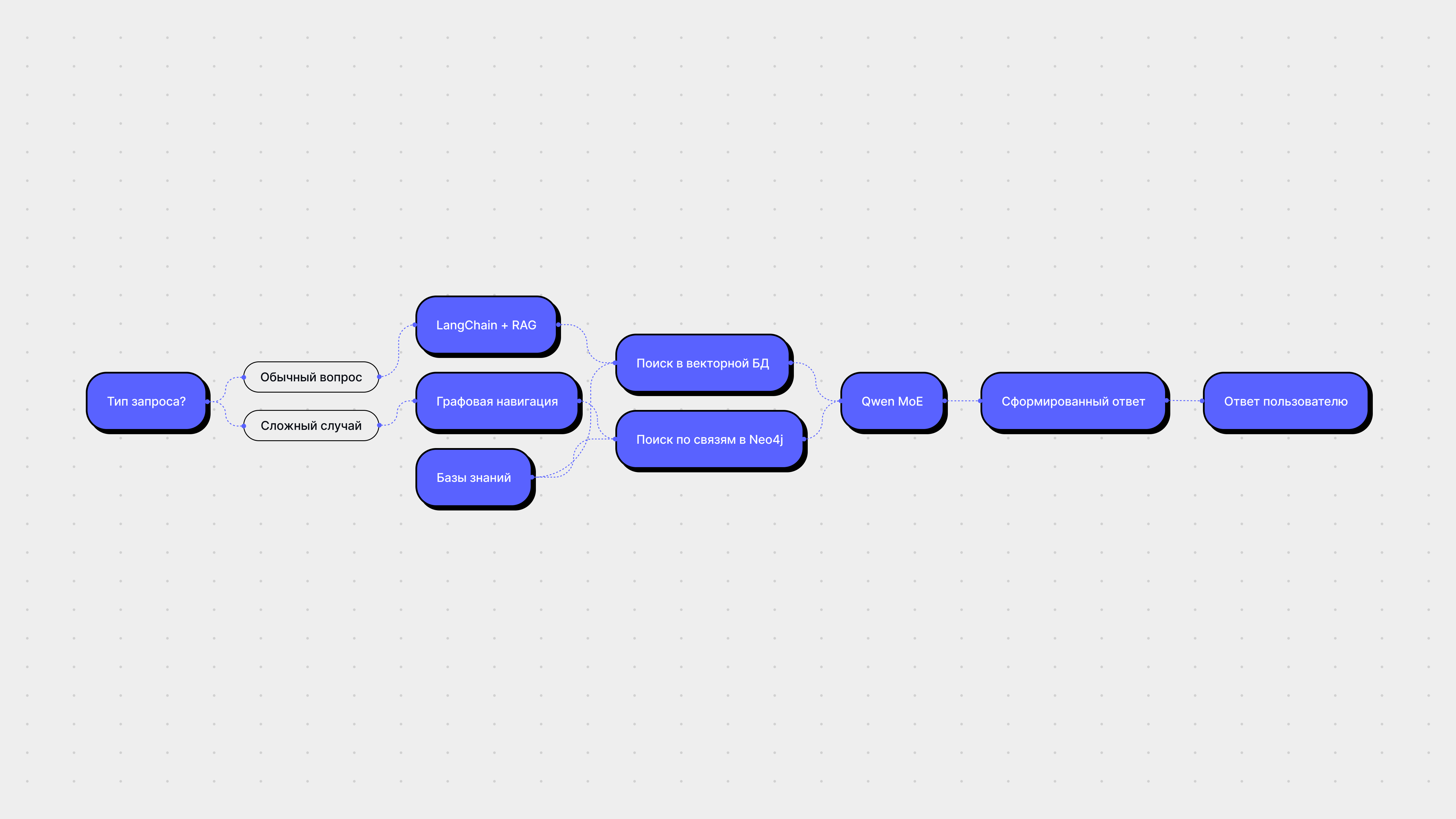
Обработка запросов пользователей
Далее подробнее расскажем о том, какой путь система проходит от запроса до ответа пользователю.
Шаг 1: Переработка баз знаний — не просто хранение, а умная структура
Проблема: Изначально базы были в виде «страниц» — технические описания, PDF, FAQ без единой структуры. Поиск был медленным, ответы — неточными. Решение:
Разделение на актуальную и архивную информацию
— Актуальная: используется в RAG;
— Архивная: доступна только по явному запросу (например, «А было ли такое в старых версиях?»).
Переформатирование в формат «Вопрос — Ответ»
Каждый фрагмент — пара:
Q: Как подключить датчик X к плате Y?
A: Через интерфейс I2C, используя пины SDA=5, SCL=6...
Это улучшает релевантность при семантическом поиске.
Добавление метаданных
Тема, продукт, уровень сложности, тип устройства, дата актуальности.
Позволяет фильтровать результаты поиска.
Шаг 2: Внедрение графовой структуры знаний
Утверждение: Не все вопросы решаются одним документом. Иногда нужно пройти по цепочке: датчик → протокол связи → пример кода → совместимость с платой → питание
Реализация:
Используем Neo4j как графовую БД.
Создаём узлы:
(Article), (Device), (Protocol), (UseCase).
Связи:
:RELATED_TO, :USES_PROTOCOL, :COMPATIBLE_WITH, :EXAMPLE_FOR.
При запросе «Как подключить MPU6050 к Arduino?» система находит статью и автоматически добавляет ссылки на пример кода и описание протокола.
Шаг 3: Дополнительная база — «Электроника и робототехника»
Что добавили:
— Статьи по практическому применению деталей;
— Схемы подключения.
Распиновки: советы по питанию, уровню напряжения, совместимости.
Преобразование:
— Все статьи разбиты на чанки;
— Загружены в векторное хранилище (например, Pinecone или Weaviate);
— Проиндексированы с метками: electronics, robotics, how-to.
Особенности выбора технологий
Почему Qwen MoE?
— Высокая производительность при меньших затратах (MoE активирует только часть экспертов);
— Хорошо работает с техническими текстами и англо-русским контекстом;
— Поддерживает длинные контексты (до 32k токенов) — важно для объединения графа и документов.
Оркестрация через n8n
— Приём запросов из разных каналов: чат-бот на сайте, email;
— Триггеры: если вопрос не решён — отправить в живую поддержку;
— Логирование, аналитика, SLA-мониторинг.
Плюсы:
— Гибкость: легко добавлять новые источники (например, Notion, Confluence);
— Аудит: все запросы и ответы логируются;
— Автоматизация: можно запускать обучение модели при росте числа неразрешённых вопросов.
Минусы:
— Если бы система была более высоконагруженной, более стабильным вариантом был бы выбор в пользу кастомной оркестрации.
Некоторые детали за пределами основного пайплайна разработки
1. Формализация процесса обновления баз знаний
Даже самая хорошая БД устаревает. Кроме работы с имеющимися данными и разработкой решения, мы обсудили с клиентом и зафиксировали следующие вопросы:
— Кто и как обновляет базу?
— Есть ли события-триггеры для таких обновлений?
— Как проверяется точность добавленной информации?
Написали автоматизированные пайплайны добавления данных в БД, где это допустимо.
Добавили флажки типа «последний раз проверено» и напоминания о периодическом ревью данных, версионирование контента
2. Добавили автоматическую генерацию новых связей в графовой структуре
Если делать их вручную, они могут оказаться неполными. Новые связи генерируются, например, при добавлении нового продукта / карточки товара.
Автоматическое извлечение связей через LLM:
— Например, если в тексте есть «используется с Arduino», → создаётся связь: COMPATIBLE_WITH→Arduino;
— Можно использовать NER + relation extraction (например, с помощью mini-LLM).
Настроили регулярное сканирование документов на наличие новых ссылок.
3. Добавили механизм обратной связи, чтобы дать возможность системе учиться на своих ошибках
Если ассистент дал плохой ответ — он не узнает об этом, если не настроить фидбэк.
Добавили кнопку «помогло?» в конце каждого диалога. В случае, если система не помогла, запрос и контекст поиска сохраняются, и анализируются впоследствии во время дообучения.
Эти данные затем используются для дообучения эмбеддингов, prompt engineering-а, а также создания новых чанков информации в БД.
4. Прочая обратная связь и сбор информации о поведении решения на проде
Для последующего улучшения модели также собирается следующая статистика:
— Какие вопросы чаще всего не решаются? → сигнал к улучшению базы;
— Какие статьи чаще всего возвращаются в поиске? → самые ценные.
10% случайно выбранных ответов модели отправляются на ручную проверку опытных операторов поддержки. Они вручную производят факт-чекинг, эти проверенные ответы также сохраняются в базу для дальнейшего улучшения системы. Остальные 90% ответов модели перед отправкой также проверяются небольшой LLM, ее вердикты записываются в базу для дальнейшего улучшения системы.
5. Сделали шаблонизацию сложных ответов
Это значительно снижает риск галлюцинаций. Например, «Для подключения — всегда указывать: Пин X → Y, Напряжение: Z, Пример кода: есть/нет.»
Сотрудники
Карина Садова
руководитель направления AI